Who Shapes AI Search? The Influence Mechanics Behind Every Answer You See
The people shaping AI are not the loudest or the most numerous. They are the ones producing the most structured, repeatable, high-signal interactions.
The Question Nobody Is Asking
In Part 1, I mapped how search evolved from ranking documents to assembling evidence — how Google built the web through technical SEO standards, and how AI systems now fragment that single optimization target across multiple platforms.
But that analysis left a deeper question unanswered: if AI systems are assembling answers from human-created content, who is actually creating the patterns those systems amplify?
The answer is surprisingly concentrated. And the implications are significant for anyone who creates content, builds products, or makes decisions based on AI-generated information.
This started as a thought experiment about my own search behavior — noticing when I reach for Google versus ChatGPT versus Amazon, and why. It turned into something much larger: a map of how a tiny fraction of users are shaping the knowledge layer that billions interact with.
The Scale of the Asymmetry
The raw numbers reveal a dramatic concentration of influence.
Compare this to Google: 8.5 billion searches per day, with over 90% global market share. Google’s user base is effectively the entire internet population — all ages, all skill levels, all intents. AI’s active user base, especially the paid tier, is a narrow slice of technically literate early adopters.
Who Uses AI (Demographics)
| Dimension | AI Users | Google Users |
|---|---|---|
| Age | ~65% under 35 | All age groups |
| Skill Level | Digitally native, early adopters | Full spectrum |
| Primary Use | Research, writing, synthesis, building | Everything: lookup, shopping, directions, entertainment |
| Work Usage | ~28% of US workers use ChatGPT at work | Nearly universal |
| Geography | US (~19%), India (~8–13%), concentrated in developed economies | Global, near-universal |
This creates a contradiction that most people haven’t fully articulated yet: we’re in a hybrid phase where traditional search still exists and is still reinforced by the behavior of billions of users — but AI search is being shaped by a much smaller group of current power users.
Only a small percentage of the world is actively using paid AI tools right now. But that group interacts deeply, frequently, and intentionally — and their behavior is feeding back into how AI systems learn to serve answers. The future of search is being trained by a few while still being consumed by the many.
And as adoption grows, those early patterns don’t disappear — they compound. The “default answers” of tomorrow may reflect a narrow slice of today’s users. What happens when a system trained disproportionately by a minority becomes the primary interface for everyone?
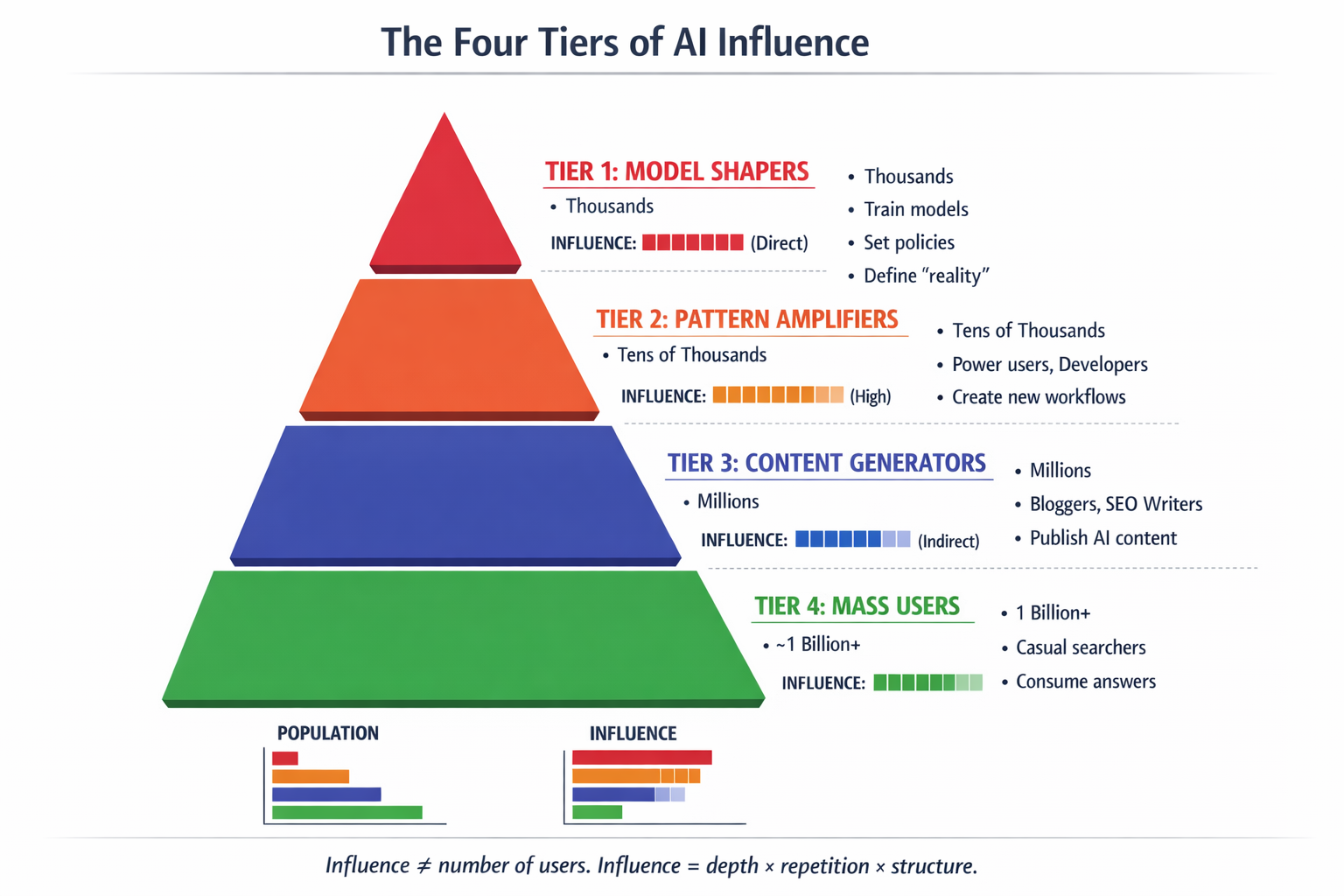
The Four Tiers of AI Influence
Not all AI users contribute equally to what the system learns and amplifies. Influence in AI isn’t a function of how many people use it — it’s a function of signal density per interaction. Here’s how the tiers break down:
Tier 1 Model Shapers
Who: AI researchers at OpenAI, Anthropic, Google DeepMind. RLHF trainers and labelers. Enterprise clients feeding proprietary workflows. API power users running automation at scale.
What they control: What the model learns during training and fine-tuning. What gets reinforced. What gets suppressed. They directly affect the model’s internal weights and behavior policies.
Scale: Thousands of people. Upstream control of what “reality” looks like to the model.
Tier 2 Pattern Amplifiers
Who: Developers, engineers, cybersecurity practitioners, startup founders, power users on paid plans, anyone doing non-trivial technical work with AI tools.
What they do: Ask complex, edge-case questions. Stress-test models. Discover new workflows. Generate novel solutions that define what “good answers” look like for categories of problems.
Why they matter: Their interactions create new patterns. Those patterns get reused by other users, mimicked in content, and influence future tuning cycles. One developer generating structured, repeatable solutions has more system-level impact than thousands of casual users asking simple questions.
Tier 3 Content Generators
Who: Bloggers, YouTubers, SEO writers, people publishing AI-assisted content.
What they do: Turn AI outputs into web content. Reinforce patterns into the public web. Feed the retrieval layer that AI systems query at runtime.
Impact: Indirect but scalable. They don’t shape the model’s reasoning, but they shape the content ecosystem the model retrieves from.
Tier 4 Mass Users
Who: Casual users, free-tier users, students asking occasional questions, people using AI for simple lookups.
What they do: Consume outputs. Rarely generate new patterns. Low signal density per interaction.
Impact: Minimal individually. They are the audience, not the architects.
The Feedback Loop: How Individual Solutions Become Collective Defaults
The most important dynamic in AI search isn’t the technology. It’s the feedback loop between human problem-solving and system reinforcement.
In the old model, knowledge diffusion was fragmented: 100 people might solve the same problem independently, 10 might write about it, 3 might get visibility, and you might find 1 or 2 through search. Now, AI systems aggregate across all of them and redistribute a synthesized “best” version to everyone who asks.
That’s an enormous compression of human trial-and-error. But it comes with structural risks.
The Upside
Rapid knowledge diffusion: One person solves a problem, millions benefit quickly. Innovation cycles compress.
Collective intelligence scaling: AI becomes externalized memory of human problem-solving. Less duplication of effort.
Higher starting baseline: New entrants to any field can start from the aggregated best practices instead of rediscovering them from scratch.
The Risks
Premature convergence: The system locks onto a solution too early. Early solutions get more visibility, repeated patterns look “correct,” and AI reinforces consistency over correctness. Suboptimal solutions become standards.
Loss of solution diversity: Multiple approaches get compressed into one narrative. Edge-case solutions, unconventional methods, and experimental approaches disappear.
Consensus bias amplification: AI favors patterns that appear frequently and consistently. But frequency does not equal correctness. Majority opinion dominates; minority insights get suppressed.
Invisible standardization: Users believe they’re making independent decisions. In reality, AI guided thousands of users toward the same pattern. The illusion of independent thinking with the reality of system-directed convergence.
“The future is not about who creates knowledge. It’s about who controls how knowledge is aggregated and redistributed.”
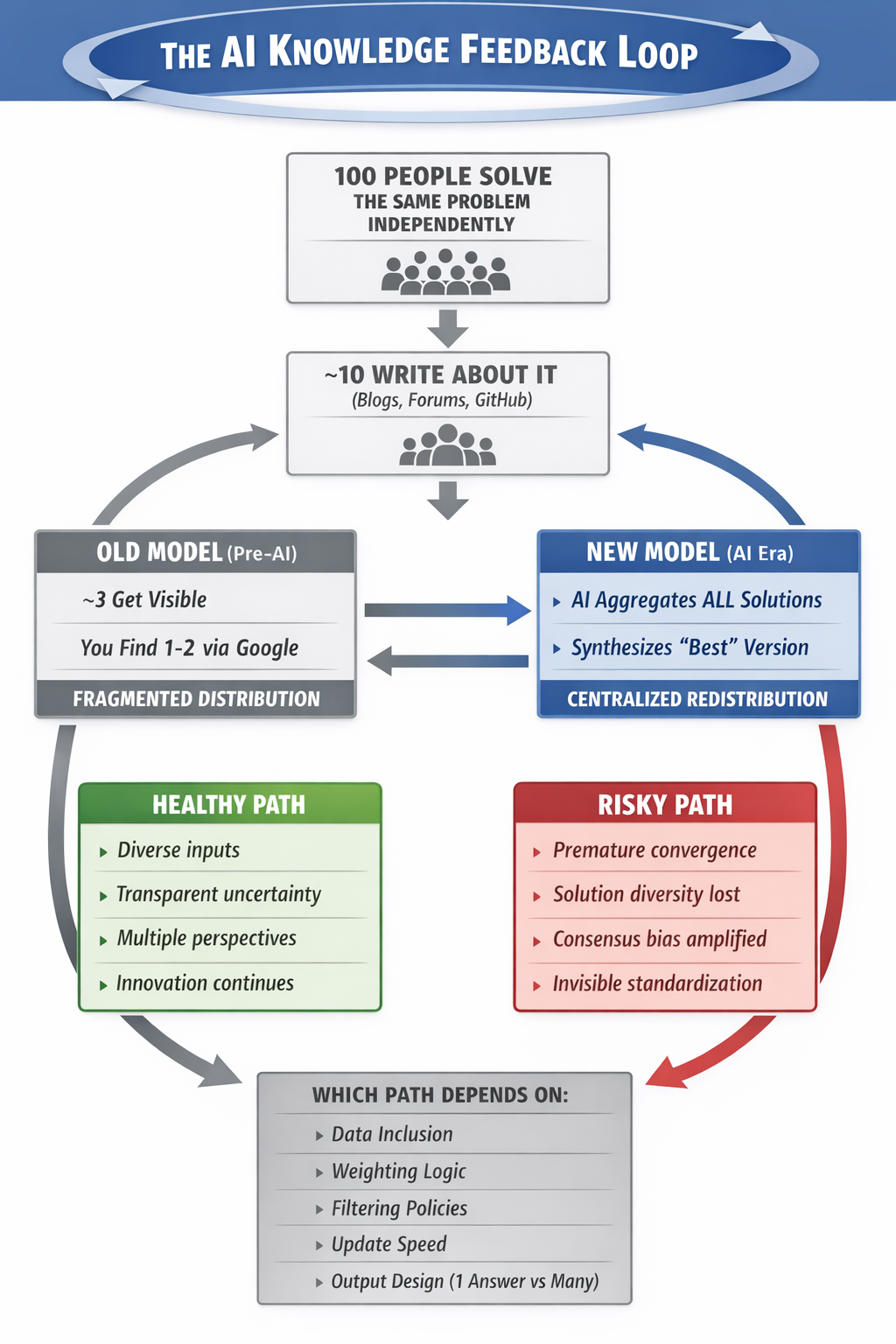
Old model: fragmented discovery. New model: AI aggregates all solutions and redistributes one “best” version to everyone.
Two Different Power Structures
Google and AI systems amplify human behavior — but through fundamentally different mechanisms.
| Dimension | AI Systems | |
|---|---|---|
| What gets amplified | What people click | What patterns persist across interactions |
| Influence distribution | Distributed — everyone contributes via clicks | Concentrated — heavy/paid users dominate signal |
| Feedback speed | Real-time (clicks → rankings) | Delayed (usage → training cycles → future outputs) |
| Transparency | Somewhat visible (you can see rankings change) | Opaque (you can’t see what influenced the answer) |
| What “truth” means | Popularity = visibility | Pattern consistency = likelihood of output |
The Five Control Points
The feedback loop is not neutral. Its behavior depends on five variables — and whoever controls these controls the knowledge layer.
1. Data Inclusion
What enters the training and retrieval pool? Public web vs. private data, forums vs. academic sources, high-quality vs. noisy content. Whoever controls this controls what reality looks like to the model.
2. Weighting
What signals matter more? Popularity, authority, recency, consistency? Different weighting produces different “truth.” A system that weights recency heavily will give different answers than one that weights consensus.
3. Filtering
What gets removed or suppressed? Safety filtering, content policies, and quality thresholds all shape the range of possible answers. This is where the boundary between responsible curation and opinion suppression gets blurry.
4. Update Speed
How fast does the system adapt? Slow updates mean stability but staleness. Fast updates mean adaptability but volatility. This affects the innovation-vs-stability balance of the entire knowledge ecosystem.
5. Output Design
Does the system show one answer, multiple options, or uncertainty? A system that presents a single confident answer drives convergence. A system that presents multiple perspectives preserves diversity. This design choice shapes collective behavior at scale.
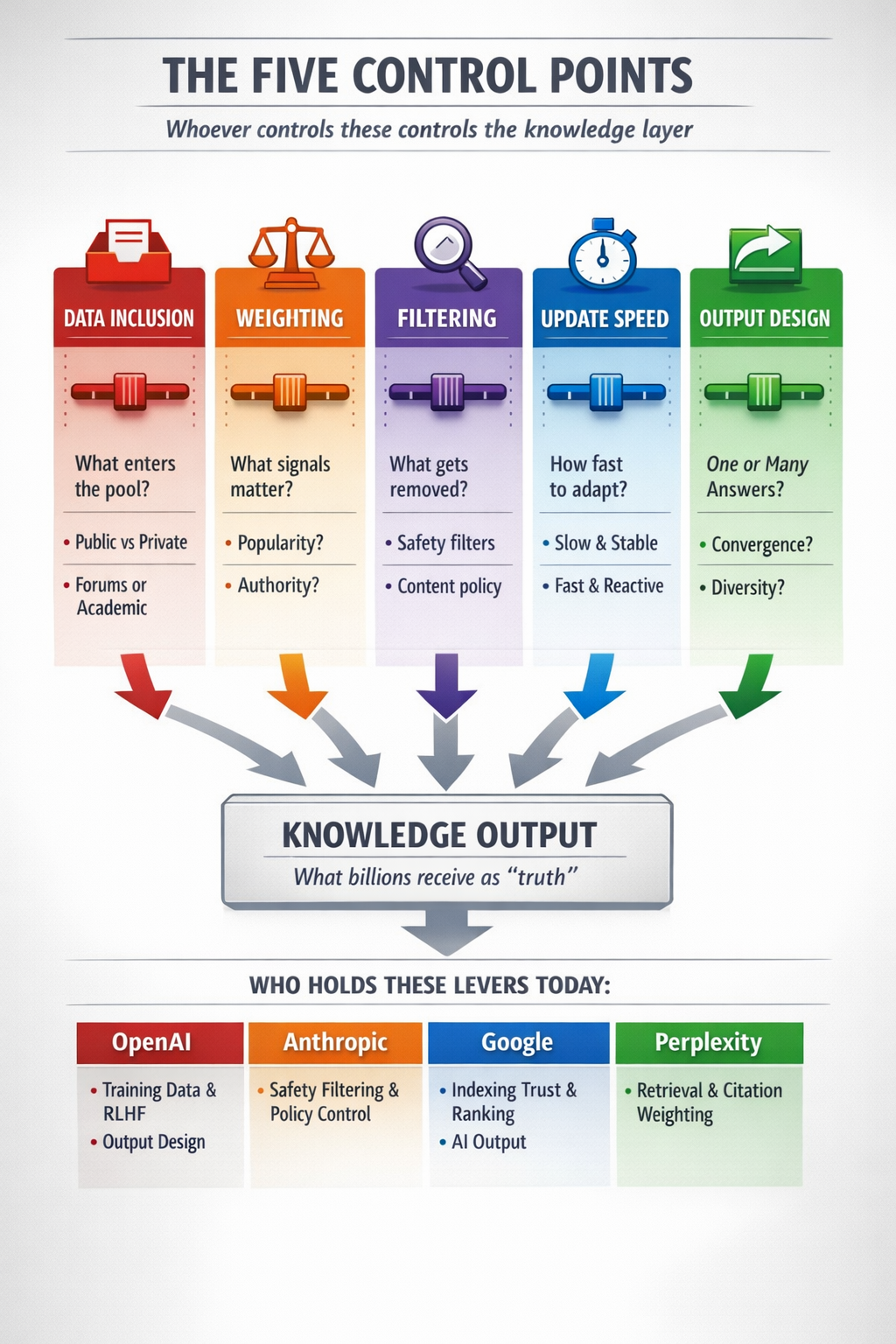
Five dials control what billions see as “truth.” Whoever holds these levers shapes the knowledge layer.
The Modern Knowledge Loop: How Search Behavior Has Already Split
This entire analysis started from a personal observation. I noticed that after 15 years of using Google as my primary research tool, I had stopped reaching for it first on a specific class of questions. When I mapped the pattern, it was clear:
The Five-Stage Knowledge Loop
1. Feeds (LinkedIn, YouTube, newsletters) → Passive signal absorption. You encounter fragments of ideas without looking for them.
2. AI Synthesis (ChatGPT, Claude) → Exploration, model-building, connecting ideas. You use AI when you don’t know what the answer looks like yet.
3. Search Verification (Google) → You switch to Google when you need a specific source, want to verify a claim, or need to find something you already know exists.
4. AI Decision Support → For complex purchases or architecture decisions, you go back to AI for synthesis across options.
5. Marketplace Execution (Amazon, etc.) → You convert on specific platforms for specific use cases, sometimes going through AI first for niche product research.
The key behavioral insight: people only Google things they already know exist. For exploration, synthesis, and undefined questions, they go to AI first. Google has become the verification layer, not the thinking layer.
This behavioral split has direct implications for content strategy. If you only optimize for Google, you’re optimizing for the verification step. You’re missing the earlier stage where people form their understanding — which increasingly happens in AI interfaces, not search results pages.
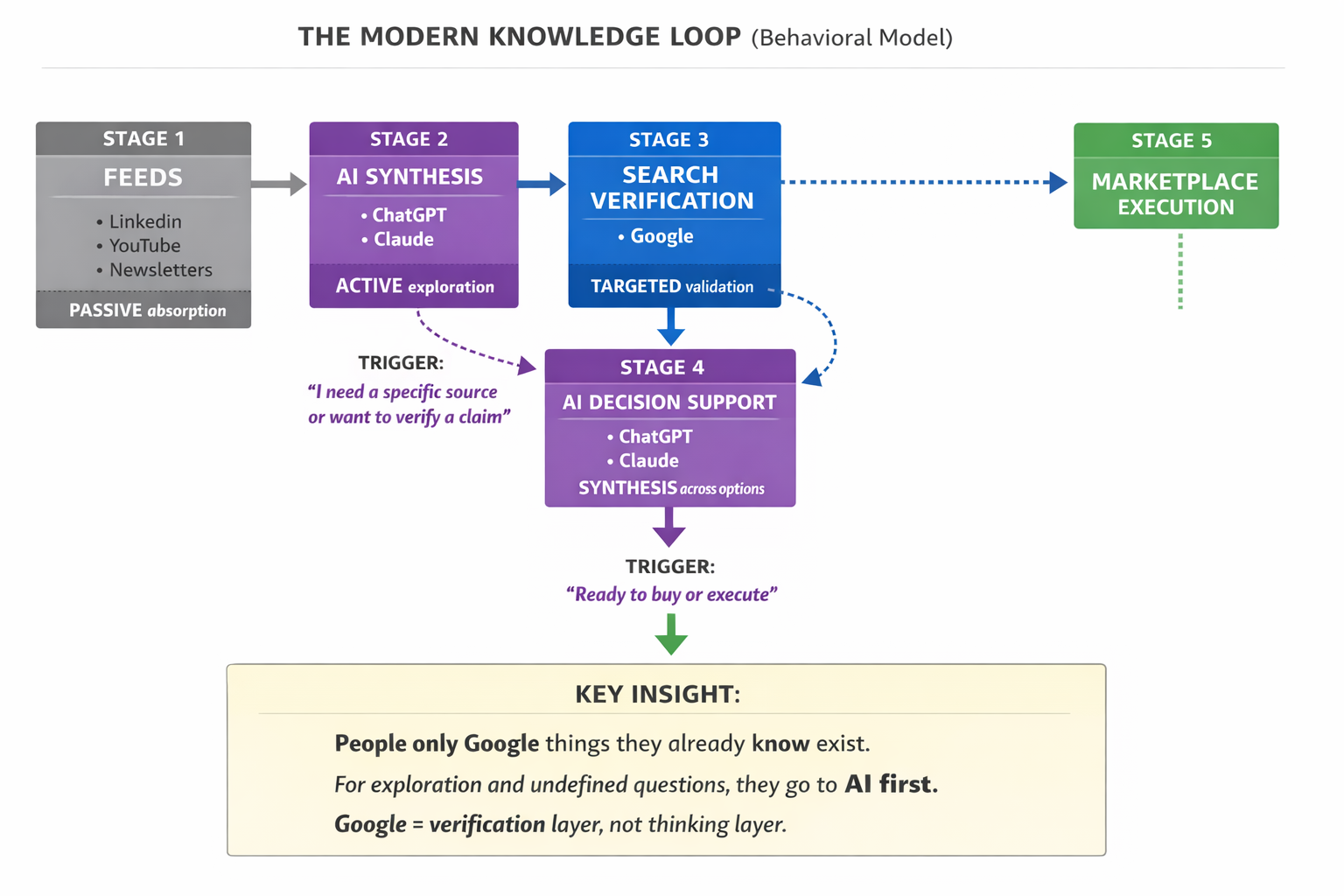
People only Google things they already know exist. For exploration and undefined questions, they go to AI first.
Pattern Artifacts: How Practitioners Shape the System
If AI systems amplify structured, repeatable patterns — and the people creating those patterns are a tiny fraction of users — then the strategic question becomes: how do you create work that enters the knowledge layer and stays there?
The answer is what I call pattern artifacts: reusable, structured representations of solutions that are designed to be referenced, extracted, and built upon.
What Makes a Pattern Artifact (vs. Regular Content)
| Regular Content | Pattern Artifact |
|---|---|
| “I set up my router for security” | “Consumer Network Segmentation Architecture for IoT Threat Containment (v1)” |
| Personal notes | Reusable framework with components, relationships, and constraints |
| One-off solution | Generalized model that applies across contexts |
| Discoverable by search | Extractable by AI systems |
The Five Layers of Dominant Artifact Design
Layer 1: Atomic Truths
Small, standalone, factual statements. “Isolating IoT devices on a separate VLAN prevents lateral movement during compromise.” These get directly quoted and reused everywhere.
Layer 2: Modular Blocks
Grouped insights: definition + mechanism + implication. Each block is an AI-extractable chunk that answers one sub-query completely.
Layer 3: System Models
Diagrams, architectures, frameworks that show how components interact. These dominate reasoning-heavy queries in ChatGPT and Claude because they provide the structural logic AI uses to compose answers.
Layer 4: Workflows
Step-by-step execution paths with decision logic. “How to detect a rogue access point: change your SSID, observe reconnection behavior, validate via packet capture.” These dominate practical queries across all platforms.
Layer 5: Meta Models
Models about systems. “What AI search systems optimize for: extractability, consensus, clarity.” This is the rarest and most powerful layer — it shapes how people think about the system itself.
The Naming Effect: Why Labels Create Leverage
One of the most underrated dynamics in information propagation: named concepts spread faster than unnamed ones.
| Generic Description | Named Concept |
|---|---|
| “network monitoring setup” | “Distributed Edge Monitoring Architecture (DEMA)” |
| “using Raspberry Pis for security” | “Defensive Pi Sandwich” |
| “detecting fake access points” | “SSID Drift Detection Method” |
Named ideas become reference points. They get cited, searched for, and linked to. AI systems latch onto labeled concepts because they provide clean semantic anchors — distinct, retrievable, and quotable. When you name a pattern, you create a node in the knowledge graph that others can connect to.
The Triangulation Effect: How to Exist Across Systems
For an artifact to dominate AI answers, it needs to exist in multiple contexts. AI systems cross-reference sources. A pattern that appears in one place is anecdotal. A pattern that appears in three places looks like consensus.
This connects directly to the cross-source agreement signal from Part 1. AI systems compare sources. If multiple independent sources converge on the same pattern, that pattern gets promoted into answers. The triangulation effect turns a single insight into a system-level influence.
Optimizing for Each Platform
| System | What It Weights | Artifact Strategy |
|---|---|---|
| Google AIO | Trust + consensus + safety | Align with known truths. Structured explanations. Conservative framing. |
| ChatGPT | Reasoning + usefulness | Build systems. Show relationships. Explain why things work. |
| Claude | Precision + logic | Remove fluff. Use exact language. No contradictions. |
| Perplexity | Retrieval + structure | Strong headings. Modular sections. Clear direct answers. |
The winning artifact — the one that gets cited across all four systems — is clear, structured, trustworthy, and generalizable. Those four qualities satisfy every platform’s selection logic simultaneously.
The Self-Reinforcing Loop: Where This Can Go Right (and Wrong)
Once a pattern artifact enters the ecosystem, it can trigger a self-reinforcing cycle:
This loop can evolve in two directions:
Healthy System
Diverse inputs. Transparent uncertainty. Multiple perspectives presented. The loop amplifies the best solutions while preserving alternatives. Innovation continues because the system exposes disagreement, not just consensus.
Risky System
Narrow inputs. Overconfident outputs. Reinforced consensus. The loop locks onto early solutions and suppresses alternatives. Innovation slows because the system presents one answer as definitive when the problem space is actually contested.
Which direction we get depends on the five control points — and on whether the people creating pattern artifacts are doing so responsibly, with awareness of the amplification dynamics they’re participating in.
The Core Insight
Part 1 established that search moved from ranking documents to assembling evidence. This article maps the next layer: who provides that evidence, and how the system decides what to amplify.
The answer is uncomfortable in its concentration. A small fraction of technically skilled users — developers, engineers, researchers, practitioners — are generating the structured patterns that AI systems redistribute to billions. The rest of us are consumers of those patterns, often without realizing we’re operating within a system that was shaped by someone else’s interaction history.
The AI era: Power = pattern creation. Whoever produces the most structured, repeatable, high-signal knowledge artifacts shapes what everyone else sees.
Understanding this doesn’t require paranoia. It requires awareness. If you create content, build products, or make decisions based on AI outputs, you are operating inside this system. The question is whether you operate as a consumer of patterns or a creator of them.
The tools to create patterns are available to anyone. The understanding of how those patterns propagate is what separates passive consumption from active participation in the knowledge layer.
References & Sources
AI Usage & Demographics:
ChatGPT Statistics & User Data — Backlinko (2025)
Number of ChatGPT Users — Digital Silk (2025)
ChatGPT Statistics 2025 — Doit Software
ChatGPT Statistics 2025: Active Users — Analytics Insight
ChatGPT Demographics & Statistics — Marketing LTB
Search Market & Comparison:
Worldwide Market Share of Search Engines — Statista
AI Overviews Study: 10M+ Keywords — Semrush (2025)
AI Usage Research (Academic):
Who Uses ChatGPT? Exploring User Demographics — arXiv (2023)
AI Usage Intensity and Distribution — arXiv (2025)
Series:
Part 1: From Ranked Lists to Evidence Assembly — How Search Changed from 2020 to 2025